One of the analogies I’m always using is how your CMS is like a physical structure such as a building or house. It’s often hard to explain how, out of the blue, a website can just plain break. But much like a house, there are many factors that come into play over time that can wreak havoc on your entire web presence.
This is particularly frustrating for website owners who figure that a website should be allowed to just sit and do its thing with little to no upkeep. After all, how can a series of 1s and 0s just change overnight?
The truth is, websites are actually way more maintenance-intensive than physical structures.
Sure, if you own a house or a building, you’ll have maintenance issues brought about by a variety of factors. Physical fixtures may break. Mother Nature brings the element of surprise to the table. Time will wear most materials down. Those are easy to understand and explain.
But how can it be that one day, your website just fails to load? How can a function break overnight, or a site to suddenly slow to a crawl?
The answer is, well…complicated.
Let’s take it piece by piece, and then I’ll explain how you can get ahead of these issues before they arise.
The Issue of (Complex) Dependencies
Dependencies are a technical term we’ll define as one segment of your application requiring another segment to properly function. When one feature cannot work unless another feature is properly functioning, you have a dependency.
This happens in the physical world all the time, though in a different way. A house needs electricity. If your power goes out, your refrigerator will lose power. Then your ice cream melts and next thing you know, you can’t have that snack you were craving on a hot day. Likewise, when the pipes freeze, the water is cut off. So much for washing clothes. These are easy to understand because frankly, in your house, there aren’t many dependencies.
Your website, however, has literally thousands of dependencies right off the shelf. Don’t forget that your website is a piece of software. It’s been designed, coded, and deployed and serves use cases like any other piece of software. As those use cases are met with functionality, dependencies are established between many moving parts. So many, in fact, that this wedding cake-inspired model should shed some light on how your site really works:
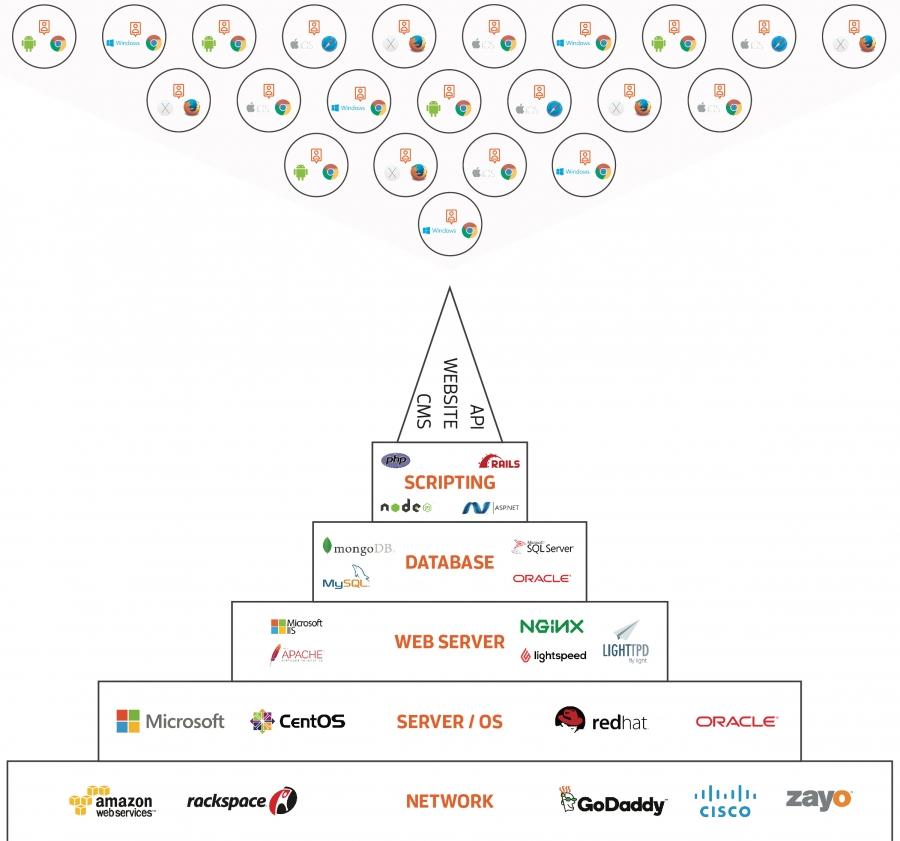
To explain this model, let’s look at the ground level.
Your website is hosted on a network. If you utilize Rackspace, Amazon, or any popular webhost, you are being served by their in-house network that connects to your server. All of those providers also have service provided to them by backbone providers. So, at any point, your web users are connecting to your website using a complex series of networks. This is the first place we look during an outage or load problem.
(Side note: I’m severely simplifying each of these components. Obviously, a network contains so many more parts such as routers, switches, load balancers, firewalls. In the interest of time, though, I’m going to take it easy on you and just focus on the top-level components.)
The next layer is the actual Server, which is powered by an operating system. A server is basically a computer. If you are on a PC or Mac reading this, you should know that you can easily configure your own device to be a web server as well. Popular server OSs are flavors of Linux, Windows, or some other fringe platforms. The operating system itself can consist of thousands of its own dependencies. Again, to simplify this article, I won’t dig too deeply, but the next time your computer goes on the fritz, consider that your web server is essentially the same system, albeit probably built on more expensive hardware.
(Another side note: Don’t be gullible. “Cloud servers” are still running on actual hardware! The cloud, after all, is just someone else’s huge computer.)
From the physical server and OS, we go to the actual software that powers the backbone of your website. This is what can be referred to as the “tech stack.” This may mean .NET and IIS in a Microsoft world. It can also mean LAMP, where Linux is the OS, Apache is the web server, and MySQL is the database, with PHP being the scripting language. There are many combinations. but all of this is simply software that sits on your web server and, when configured properly, powers your actual application. In our model above, I represent this as the web server, the database, and the scripting language.
Finally, on top of all these layers, you have your actual web application. This means your CMS, your website, and any other functionality associated with it, including APIs you may have in place.
Your CMS and the technology that it is written in is dependent on every layer underneath. If you run WordPress, you can’t function without MySQL and PHP. MySQL and PHP require an OS, which in this case can be Windows or Linux (although why anyone messes with Windows in that case is beyond me). Your OS requires proper server hardware, and all of it needs connection to a stable network and series of subnetworks to actually deliver any experience to your customers.
Each layer of this software and hardware cake has dependencies all the way down to the lowest layer. And as you can tell, there are literally thousands of places where something can blow up.
This is the reason why your website is so much more complex than a house or building. For every single thing that is functioning improperly, there are literally thousands of potential culprits.
Granted, modern software is making it easier and easier to maintain this ecosystem more efficiently. The best webhosts make worrying about network connectivity less of an issue. They may even offer up software that preconfigures servers with the tech stack you require. But even with that help, when it comes to ongoing maintenance, you have a problem. For most providers, they stop at configuration and leave it to you to handle ongoing support.
Take AWS, which is Amazon’s hosting environment. The platform is spectacular—many products and options, and superb uptime support. However, it is primarily self-service. Setting up a server instance on AWS is quick and easy, but after that, you are on your own for maintenance and support.
How does this all relate to things breaking?
Well, dependencies come into play when one element of this layer cake is either not functioning properly or needs to be updated.
Let’s take PHP for example. If you are running an old version of PHP and you update it, the process is fairly simple. However, there are dependencies that may cause issues with how Apache (a web server) handles PHP. Or perhaps how MySQL is integrated to PHP. But even worse, PHP being updated means the actual language that powers your website is affected. So, if PHP has changed some core concepts of its language, it can affect your entire site. In this example, upgrading PHP goes both upstream and downstream across multiple layers of your tech stack. Yikes!
And this happens all the time. A system administrator updates core software for security or other reasons. That update affects some software within the CMS—let’s say an installed plugin. You update the plugin, but it then breaks another plugin that hasn’t been updated as recently. Maybe then you have to upgrade your core system. This snowball effect is the major cause of maintenance hassles with off-the-shelf software. A simple upgrade can result in a series of meltdowns that takes hours to figure out.
This is one issue that causes you to wake up to a broken or severely inhibited web application. Many system administrators simply update servers with no concern or thought about the end application. Likewise, many CMS platforms have “auto” updates, which don’t think to check for dependencies underneath it.
All of these scenarios result in instability and unforeseen meltdowns.
Have you ever upgraded your CMS by hitting that unavoidable “UPGRADE” button and bad things happened? If so, then you know exactly what I’m talking about.
The Dangers of NEVER Upgrading
You may be thinking: “Why update software at all if it can cause so many problems?”
Well, the problem is, you have to.
Software updates aren’t always for new features. Sometimes they’re responses to vulnerabilities or other negative issues that have arisen within the platform itself. For example, earlier this year, we had to run updates to the core OS for any computer utilizing an Intel chip due to security concerns.
Ignoring updates is not the way to go. It just opens up a world of additional hurt!
Finally, one important element to consider when it comes to items just breaking: the user-side environment. Today’s web applications are viewed using literally thousands of devices. This means everything from mobile iOS and Android to tablets to laptops to PCs, all using different browsers, different versions thereof, and different configurations. This means that even if every part of your internal tech stack and application are working properly, you still can’t control the experience your user may be receiving simply because their local installation could be experiencing its own issues.
The Web, as a medium, is a challenging place to maintain an application and even more challenging to diagnose issues.
Sniff, Sniff… The Rot Factor
Benjamin Franklin, our founding father and O.G. polymath, is known for originating the cliché “Guests, like fish, begin to smell after three days.” I love that quote! And it applies to software too.
Software rot—also known as code rot, software erosion, or software entropy—is so prevalent, it has its own Wikipedia page.
So, what is it?
In short, it’s the slow deterioration of software performance over time. Eventually, software becomes faulty, unstable, and untenable. That’s when people start to give it the nickname “legacy,” a polite way of saying out-of-date and in desperate need of rebuilding.
Your CMS is just a piece of software. So is your website built on top of it. Much like anything else, it has a finite shelf life. This is a particularly frustrating concept to clients. “How can something like software rot? It’s not physical. Wood rots. Food rots. Software is just a collection of code that never changes.”
Sadly, this is not the case. Software over time will, in fact, deteriorate due to a variety of causes.
First, of course, is what we spotlighted earlier: dependencies. As the layers underneath the software change and evolve, it accelerates software rot. It makes CMS owners and managers create fast (and ugly) workarounds and kludges (a fancy word for hacks) to keep things running smoothly. Over time, those changes create technical debt, which we’ve covered before.
Another reason for rot can be the complete ignoring of those dependencies. If you aren’t keeping up to date at all with environmental changes such as upgrades, you are not only putting your platform at risk, but also inhibiting the growth potential of your software by not adhering to the latest standards and innovations.
Whatever the reason, when your software rots, it’s inevitable that one day, you’ll wake up to the bad news that your environment is down or some other catastrophic event has occurred. Staying on top of your platform, on the other hand, should ensure years of longevity, provided you have maintained everything properly.
This is why CMS maintenance is so important!
Defining Maintenance
So, what does “maintenance” involve anyway? Ideally, it requires the knowledge of several different skillsets which culminate in a comprehensive approach to ensuring ongoing stability and growth, both in a preventative way and from a triage perspective.
We’ve written about maintenance and its importance before, so in this post, I’d rather just summarize the key areas that need to be focused on to ensure that you don’t wake up to something broken without any advanced warning. It’s important to have, at a minimum, solidified approaches to the following areas of concern:
Server & Network
This means you are monitoring and maintaining a knowledge of your underlying network and the server running within it. You should have a way to focus on and execute updates and upgrades to the OS as necessary, and have a deep understanding of communication issues that can exist between client and server.
Tech Stack
This means an understanding of your tech stack components and how they work in tandem, in addition to how to maintain them in the same ecosystem. If you work with LAMP, you know how to maintain the tight bond from Apache to MySQL to PHP. And you understand the inner workings of how that software works together, communicates, and is accessed by both your application and the outside world.
CMS
The CMS is most often a developer’s responsibility, while the last two disciplines are the purview of a system administrator. Developers must keep on top of the changes to the underlying tech stack and server conditions in order to effectively manage how the CMS works on top of those components. In addition, if the CMS is software licensed or taken off the shelf, the administrator must know what the upgrade and update cycle looks like, how updating affects all secondary functionality like plugins, and have a deep understanding of the core framework in case they must dig deeper.
Front-End Experience
Don’t forget that the entire user interface of your application needs upkeep. Ideally, you’ll have someone who knows the ins and outs of your front-end functionality, in addition to how they integrate into the CMS platform. Issues can arise out of the blue even with front-end experience, as we highlighted earlier when we spoke about client-side environments.
As you can tell, maintaining a web application requires more than just one discipline. It requires experience with networking, server administration, back-end technology, and front-end techniques. The best way to avoid surprises is to have a team available that can handle all of these issues as they arise, or at the least understand how to diagnose from this pool of available issues.
Finally, maintenance must have a preventative component to it for each of the above categories. Server admins must manage a complex monitoring system to monitor not just if an application or website is online, but how severe the load is across a variety of indicators. CMS admins must maintain a development environment that is a duplicate of the live environment where they can test for issues without affecting real user experiences. And front-end developers must maintain their code to work in the ever-changing world of web browsers. The best maintenance strategy is preventative with workflows in place for when a true crisis arises.
With how complex the web is, how can one reduce their potential risk of malfunction?
I have a few ideas…
First: Minimize Dependencies
This may sound like a difficult thing. How can you minimize all of those dependencies that we mentioned above and actually build a robust, scalable website?
The best way is to delegate tasks to third-party tools. As an example, where in the typical scenario, a website is powered by a locally-installed (on-premises or “on-prem”) CMS platform, new technologies such as a headless CMS make it easy to offload the CMS portion to a third party. This means the CMS provider will handle hosting, updates, security, scalability, and other factors, leaving you free to focus on other things.
In that scenario, you have more options for worry-free hosting, too. You could utilize products like Amazon AWS’s S3, which can host a static website, for example. By utilizing these tools, you have reduced your dependencies by offloading responsibility.
Of course, the downside to that approach is that it will be more cost-intensive from a licensing perspective. Also, you’ll be handing over control to a third party. And you may lose some freedom and flexibility in terms of overall function. But despite these factors, if low-maintenance is what you are looking for, the many tools available today to realize that goal are an appealing option. Almost every component we have discussed today has cloud-based solutions available to choose from, meaning you can license as many parts as you wish, depending on your situation and requirements, and piece them together.
Second: Build a Team
Regardless of the approach you take in building your technology, you need a solid team to support you. In our experience, a team must consist of an amalgamation of the aforementioned disciplines, working in tandem to keep an application running smoothly. So, consider a maintenance partner that carefully addresses each particular silo of web-based technology in a cohesive way, and that has an approach to maintenance that is carefully considered and choreographed.
Also, make sure they take the time to explain how they manage updates, and monitor your application or site. If they aren’t watching 24/7/365, then how can they get ahead of potential issues?
Third: Monitor and Manage
Speaking of monitoring and managing, it’s essential that you have systems in place to monitor every aspect of your experience. The best way to do this is multi-pronged.
Automated monitors should be making sure your application is responding to the world, and not just load time or by “pinging” the server. It should check for memory usage, CPU usage, disk space availability, and other factors so that it can predict issues before they are even noticeable to the end user.
This should also mean testing of the functionality of your site. Key components should be tested on a regular basis. If your site is for lead generation, then you should be testing contact forms and any other functionality that matters: logins, registration, e-commerce checkouts, etc.
In addition to automated means, the best maintenance partners would also have a manual component. We like to create a script for our team to manually run through on a regular basis to get ahead of potential issues. This manual process also gives us the opportunity to suggest fixes and new features ahead of any future problems.
Wrapping Up
Nothing is more frustrating to a client than when their website or application just stops working out of the blue. It’s frustrating for us, too. It doesn’t look good. It’s easy to explain, but hard to understand. Hopefully, this post clears up why these incidents happen and how you can avoid these hassles via smart technical decisions early in the process, as well as ongoing support and monitoring.
Technical applications will always require more maintenance than you ever thought necessary, but with planning and proper execution, surprises can be avoided and stress minimalized.

